On November 18th, 2025, Gemini 3 (including the “Pro” version) was officially introduced to the world by Google LLC as the latest version of its most popular family of large-language multimodal models. The company claims that it is “our most advanced models”; Gemini 3 combines multimodal understanding (text, images, and video) with advanced reasoning and capabilities for agents, enabling more autonomous actions and more immersive interactive experiences.
This is a comprehensive overview of Gemini 3’s features, what it brings, how it differs from earlier versions, how to get it, what it can mean for users and builders, and a few frequently asked questions.
What is Gemini 3?
Gemini 3 is the most recent version of Google’s Gemini model line-up, which follows previous releases like Gemini 2.5. According to Google’s blog, Gemini 3 is designed to “help you bring your ideas to reality” by enabling better understanding of context, multimodal input, reasoning, planning, and tool use.
The key dimensions are:
- Multimodal Comprehension: Gemini 3 is designed to reason over images, text (and, in some instances, other modalities) in conjunction.
- Tool-use or Agentic Ability: More advanced than simply responding to text questions, it can complete tasks, use external tools, and adopt planning/agent-style workflows.
- Enhances Creativity and Reasoning: Google says this generation is significantly ahead of previous benchmarks in reasoning, coding and multimodal tasks.
- Wide Product Integration: Gemini 3 is currently being integrated into a variety of Google services (such as the Gemini application, Search’s AI Mode Developer tools), as well as enterprise and developer platforms.
In other words, rather than simply being a chat model, Gemini 3 is intended to be a “general-purpose intelligence” layer in Google’s ecosystem.
What’s new compared to previous versions?
Here are the main improvements:
| Area | What Gemini 3 improves |
|---|---|
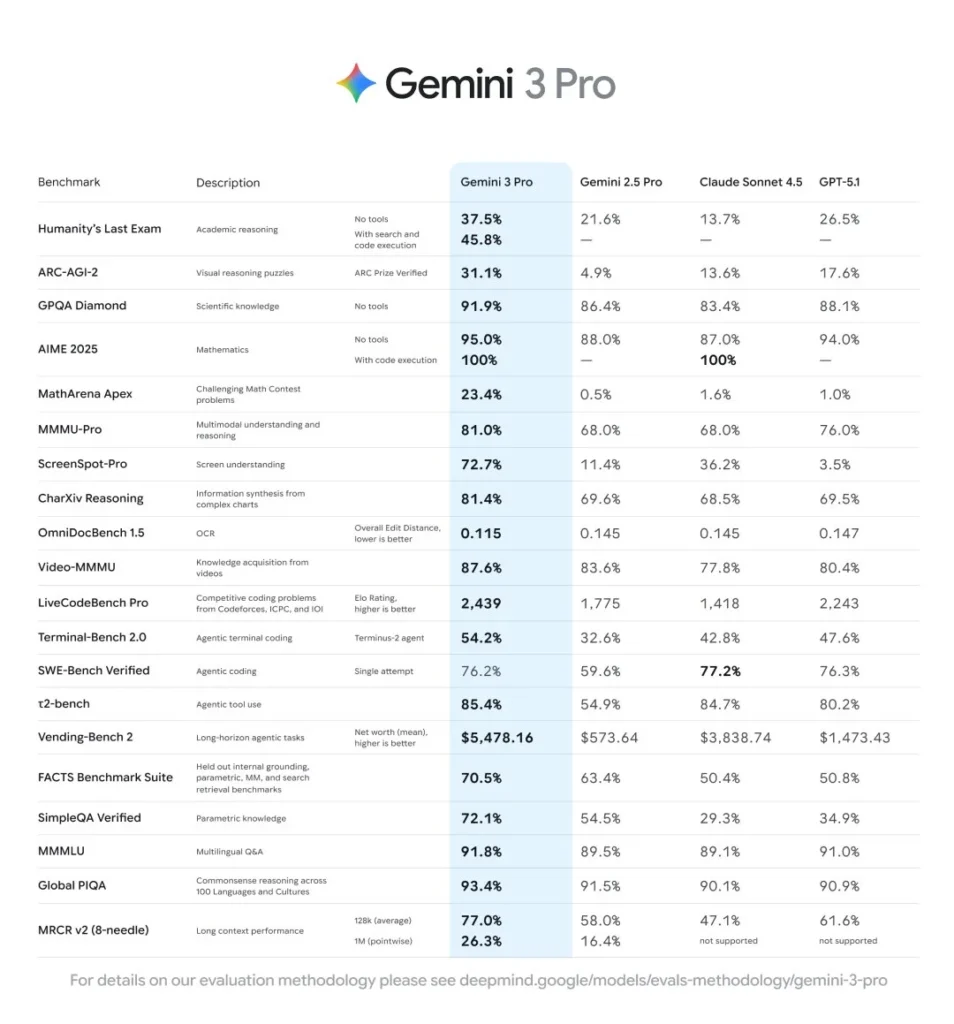
| Reasoning & benchmarks | According to reports, Gemini 3 outpaces Gemini 2.5 (and earlier) on key reasoning and multimodal tasks (for example, solving harder problems in fewer steps). |
| Multimodal fluency | Stronger ability to combine text + image inputs (and potentially more modalities) and generate richer, coherent outputs. The updated Gemini app notes enhanced multimodal understanding. |
| Agentic / tool capabilities | More “agentic” behavior: ability to plan, call tools, manage contexts, interact with external data or environments. Google mentions “bring any idea to life” and “build anything” with Gemini 3. |
| Deployment and ecosystem | Rather than being restricted to one interface, Gemini 3 is rolling out across the Gemini app, Google Search AI Mode, developer APIs (e.g., via Gemini CLI), and enterprise platforms like Vertex AI. |
| Product experience / interfaces | New user-facing features, such as “generative UI” in the Gemini app (interactive views, visual layouts), improved integrations. |
Therefore, for both developers and end users, Gemini 3 represents a significant upgrade.
How can you get it?
Let’s see the way Gemini 3 is being made available:
For general users
- The Gemini application (on web and mobile) is now updated with Gemini 3 capabilities. The blog post explains that”major update” begins today “major update” will begin.
- “AI Mode” in Google Search “AI Mode” (in Search) now incorporates Gemini 3 (or at least its preview) to give queries greater understanding.
For developers & enterprise
- The Gemini 3 Pro model is now available. The Gemini 3 Pro model is now available through the Gemini CLI for those who have access (for instance, Google AI Ultra subscribers or those who pay for API keys).
- Also accessible (or in the near future) through Google Cloud’s Vertex AI and other enterprise integrations.
Notes on rollouts
Although the announcement is made immediately, the rollout of the full feature set could be gradual. Regions, tiers, features, and regions could be released over time. For instance, developers have noticed mentions of Gemini 3 in AI Studio before an official public activation.
Use-cases: What do you have to do to accomplish using Gemini 3?
With the new abilities, there are some major scenarios to be considered:
- Learning and knowledge work: Better reasoning helps with deep diving, tutorial planning, and the synthesis of multimodal content (images plus text) more efficiently than before.
- Creative generation: Thanks to the better processing of multimodal inputs, Gemini 3 can generate richer outputs (text + images and scenarios) and then interactively refine them.
- Programming and Software Creation: Developers, it is important to know that the “agentic” abilities provided by Gemini 3 Pro are especially suitable for tasks such as code generation and automation, tool orchestration, and the creation of end-to-end workflows.
- Enhances Search productivity: With Search’s AI Mode, users may receive more informative, contextually aware responses. This goes beyond simple query-response and more toward an assistant.
- Enterprise applications: Integration of Gemini 3 into business workflows (via Vertex AI, etc) in which high-level reasoning plus multimodal input and automation are important (e.g. documents, images and planning).
Responsible development & safety
Google insists that Gemini 3 is rolled out with responsible AI methods. The blog says that the Gemini 3 model is “generative AI is experimental” and that they are continuing to improve the safety as well as privacy, fairness, and alignment security measures.
With the growing use of agents in the tool (which could drive automation or calls from outside), developers and organisations must integrate safeguards, monitoring, and human-in-the-loop supervision.
What does this mean for the AI landscape?
- Gemini 3 is the latest version of Gemini 3. Gemini 3: Google is making breakthroughs in its AI capabilities and bolstering its position in the competitive large-language model (LLM) market.
- For developers and users alike, the introduction of more sophisticated AI into existing tools (Search Mobile App development tooling) implies a change in how AI becomes more integrated, not simply “one other chat app”.
- Developers and companies may view LLMs as Gemini 3 not just as assistants but also as “agents” (i.e., models that plan, take action, and connect), raising governance and opportunity issues.
- For search, content, and the wider web ecosystem, devices like Gemini 3 may accelerate how “answers” are provided and could impact how people find and consume information on the internet.
Final thoughts
Gemini 3 represents a significant step in Google’s AI plan. By combining sophisticated multimodal reasoning, understanding, and agent-like tool usage into a single model and extending it across their entire ecosystem (search apps, developer tooling), Google is making the case for a better-integrated AI assistant.
For ordinary users, it means more efficient interactions across the Gemini and Search apps. For businesses and developers, it opens new opportunities; however, it also creates new responsibilities in terms of security, governance and integration.
As with all generative AI, it’s a high-risk proposition; however, it’s essential to be cautious when using it. If you’re interested in the technology and are eligible, this is the perfect time to try Gemini 3 and see how it works with your workflow and concepts.
FAQs
1. When will Gemini 3 be available?
The announcement date is November 18th, 2025. The rollout of Gemini’s Gemini application and AI Mode in Search begins today. Developer access to the Gemini CLI and API is also available to users who meet the requirements. Full worldwide availability across all devices and tiers could take a while, depending on how Google is phasing the rollout.
2. What is “Gemini 3 Pro “?
“Pro” is the higher-end version designed to handle more challenging tasks, particularly for coders, developers, and automated workflows. For instance, Gemini 3 Pro is the default version of Gemini CLI for eligible subscribers.
3. What is the difference between Gemini 2.5 and before?
While earlier Gemini versions included multimodal and reasoning capabilities, Gemini 3 upgrades them significantly: better benchmark performance, more efficient agent/tool use, greater integration between products, and more multimodal capabilities. For instance, benchmark reports reveal significant improvements.
4. Is it only for the English language?
The announcement addresses global rollouts, and Google generally supports multiple languages, even though the blog itself is centred on English. As Gemini expands, support for multilingualism is expected. (In the earlier Gemini versions, Multimodal and multilingual support was included.)
5. What are the limitations and exclusions?
Despite all the advancements, Google notes that generative AI is still experimental. The outputs should be considered helpful rather than definitive. Safety, accuracy, and tools integration require oversight by humans. Additionally, feature availability may depend on the subscription level, region, or device.
6. How can developers begin building using it?
Developers: update to the latest Gemini CLI version (for eligible subscribers), as detailed in Google’s developer blog. For developer and enterprise platforms, check Vertex AI and Google Cloud to see if they are available. Also, keep track of documentation to determine API accessibility, rate limitations, prices, etc.