In the last quarter of 2025, the edge of artificial intelligence’s reasoning witnessed drastic shifts in the ARC-AGI-2 benchmark, a rigorous examination of fluidity of reasoning as well as general problem-solving, achieved breakthrough results using two different sources: the meta-system of Poetiq, as well as the OpenAI GPT-5.2, the X-High system.
These results have not only raised standards of performance but also provoked debate on how to improve general intelligence. This article summarises the most recent confirmed findings, explains the implications they have for AI studies, and puts them in the context of previous advancements.
What Is the ARC-AGI-2 Benchmark?
The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI-2) is a follow-up to the original ARC AGI test. It was created to test an AI’s capacity to do abstract reasoning and generalisation from simple examples, which is a key feature in fluid intelligence. The test is comprised of a grid of puzzles that require understanding the underlying rules that transform inputs into the correct outputs. In contrast to typical AI tests, the ARC AGI-2 tasks can be solved by humans in time-limited situations and focus on conceptual reasoning instead of memorisation.
ARC-AGI-2 includes:
- Sets of public training and evaluation that developers can utilize to test models.
- Semi-private test sets and private test sets are used to verify leaderboard scores, to prevent overfitting.
The benchmark’s difficulties have been a constant source of AI systems’ performance at a low level. Early results for leading models were often in the single digits.
ARC-AGI-2 Benchmark: The Poetiq Breakthrough
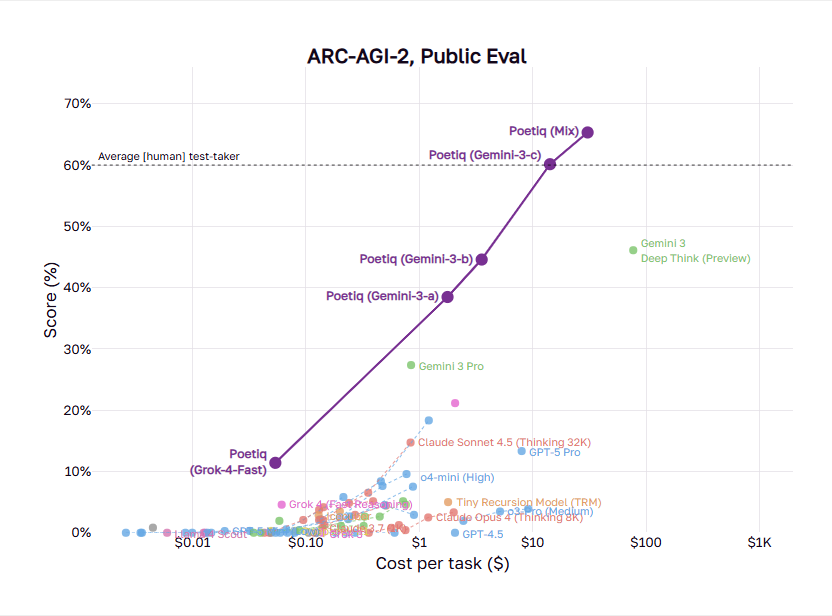
Poetiq, an initiative for research dedicated to sophisticated reasoning algorithms, has recently announced a significant improvement to the ARC-AGI-2. Utilizing a meta-system that does not train new models, but rather orchestrates existing large-language models (LLMs) using loops of reasoning that iterate, Poetiq achieved:
- 75% accuracy for the entire PUBLIC-EVAL dataset by employing GPT-5.2 X-High. This is an average cost of just $8 per case.
- The official verification of the semi-private test set at 54% accuracy, which is approximately $30.57 per task. This is the first attempt to cross the threshold of 50% and set a new, state-of-the-art record.
The performance was significantly superior to previous top contenders, such as Google’s Gemini 3 Deep Think configuration, which scored about 45% under similar conditions of semi-private, as well as other advanced model pipelines.
The main difference between the two approaches is that it didn’t provide specific model-specific training to ARC-AGI-2; instead, it utilized innovative orchestration and evaluation strategies to gain better reasoning of general-purpose LLMs.
ARC-AGI-2 Benchmark: GPT-5.2 X-High: A Competitive Force
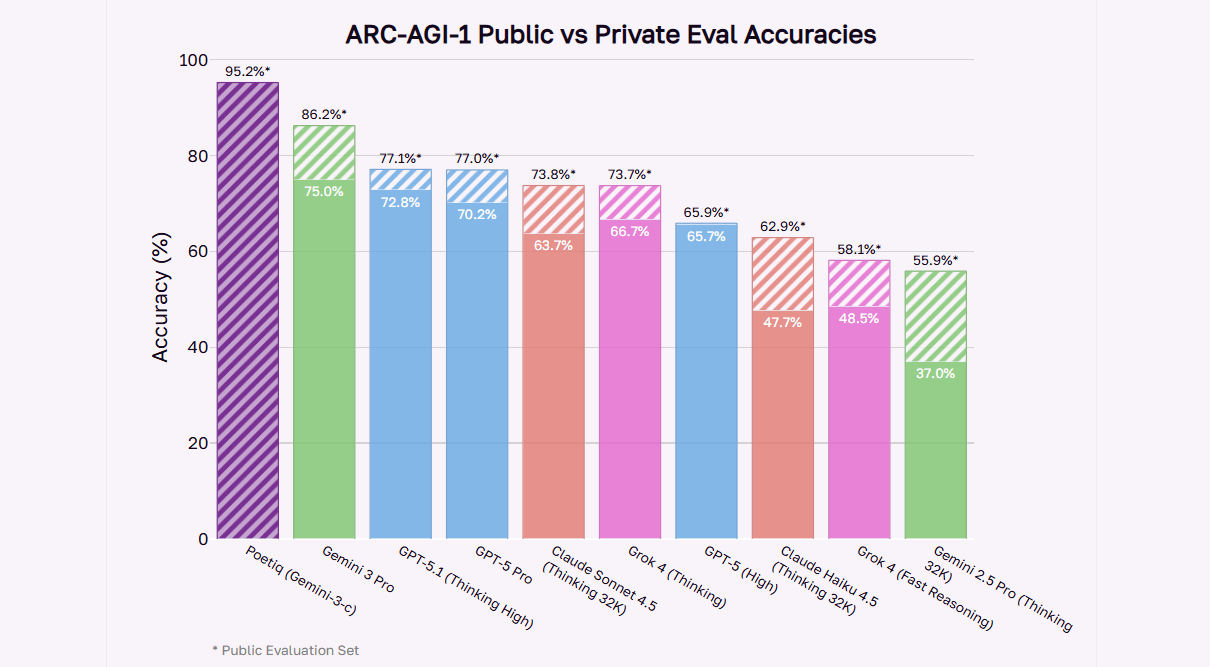
Similar to Poetiq’s results, the OpenAI GPT-5.2 The X High strategy (a top variant that is part of the GPT-5.2 family) performed admirably on the entire PUBLIC-EVAL ARC – AGI-2 dataset, which reported:
- The accuracy can reach 75, an improvement over prior benchmarks, and about 15 percentage points higher than the previous state of the art.
Importantly, GPT-5.2’s performance was reported without specialized tuning for ARC-AGI-2. This highlights the reasoning enhancements that are built into the model.
Although this is typically associated with benchmarks that are public tests, rather than semi-private verification, it provides excellent evidence that GPT-5.2’s superior abstract reasoning capability in comparison to older models, many of which struggled with the most difficult ARC-AGI-2 tasks.
Why These Results Matter?
1. Returning to Core Reasoning
The ARC-AGI-2 algorithm was specifically designed to test AI systems by requiring rule inference and conceptual understanding, rather than merely pattern recognition. The reality that both the orchestration of Poetiq, along with GPT-5.2 X-High, can achieve a majority performance suggests that the field is progressing towards real reasoning capability and not just the performance of tasks at a surface level.
2. Bridging the AI Capability Gap
For a long time, benchmarks such as AGI’s ARC-AGI demonstrated significant differences between human and AI performance. While humans can solve 100 percent of the tasks they are assigned, typical AI systems had extremely low rates of success early in 2025. Recent research has narrowed this gap considerably and signals an exciting new stage in the development of AI.
3. Cost-Efficiency in Reasoning Systems
The reported costs of Poetiq, which are as low as $8 for each problem in benchmarks for public use, illustrate the changing economics of the latest AI reasoning. Optimized architectures that increase efficiency per computing unit will be essential for the scalable implementation of AI within real-world applications.
4. Model-Agnostic Techniques Triumph
The IRC-AGI-2 results of Poetiq were obtained without the use of new model training techniques, proving the effectiveness of meta-reasoning frameworks that elevate models off the shelf. This highlights the need to move towards systems that can intelligently combine and analyze outputs, rather than relying on only the raw size of models or data.
ARC-AGI-2 Benchmark: Broader Implications for AI and AGI Research
The ARC-AGI-2 results have ignited discussion within the AI research community on how progress towards Artificial General Intelligence (AGI) should be evaluated. While achieving the performance thresholds in abstraction-based reasoning tests is a significant accomplishment, experts advise that these benchmarks are only the smallest portion of intelligence. Extensions such as continuous learning, the ability to adapt across different domains, and real-world problem solving are much more complicated challenges.
However, these findings redefine expectations regarding the capabilities of large models and how innovative algorithms for computational orchestration can enhance the improvement of models. They also emphasize the significance of benchmarks in monitoring progress towards intelligent, fluid AI.
My Final Thoughts
The ARC AGI-2 results associated with the results of Poetiq, as well as GPT-5.2 X-High, are more than just incremental improvements. They signal a change in the way AI reasoning performance is measured and achieved. The impressive gains that are not based on task-specific training emphasize the increasing significance of general-purpose reasoning and intelligent design of systems.
Additionally, an official validation of semi-private benchmarks bolsters the validity of these advancements and provides an example to further research. Although these accomplishments don’t necessarily mean that they are AI, they do fundamentally alter expectations regarding abstract reasoning benchmarks and suggest a future in which model improvement as well as orchestration techniques play an essential part in the development of AI intelligence.
Frequently Asked Questions
1. What distinguishes ARC-AGI-2 from previous AI benchmarks?
The ARC-AGI-2 program is a puzzle based on abstract reasoning that requires inference from a handful of examples and then generalization to new situations, and is more challenging than the typical tests that rely on patterns or massive data memory.
2. What makes the result of Poetiq significant even without model training?
The Poetiq approach doesn’t alter the basic LLM. Instead, it integrates intelligent reasoning techniques into existing models to provide superior performance, which demonstrates the importance of orchestration methods to AI reasoning.
3. Does GPT-5.2 X-High now represent the most intelligent reasoning AI?
GPT-5.2 X-High has awe-inspiring results when compared to the public ARC -AGI-2 benchmark, which achieves up to 75% accuracy with no task-specific optimization. However, semi-private or private leaderboard verification is the benchmark for fully comparable scores.
4. What are the implications of these findings for assertions regarding AGI?
Although improved reasoning performance is an important step forward, full AGI will require a strong ability to generalize intelligence across different tasks and environments. High benchmark scores by themselves are not enough to prove that AGI exists.
5. Are these results independently verified?
Poetiq’s score of 54% is officially confirmed using an unofficial test set that is used to determine leaderboard rankings. The GPT-5.2 public-evaluation results are based on reported runs using the publicly available evaluation dataset.
6. What happens next after the ARC-AGI-2?
The future benchmarks (including possible ARC AGI-3 iterations) are expected to create new and more difficult reasoning challenges and push research beyond static puzzles towards dynamic and interactive problem areas.
Also Read –
Gemini 3 Flash: A New Standard for Fast AI Models
Google Stitch Firebase Export: AI UI Design to App Flow